End-User Development for Linked-Data Observatories
Project Overview
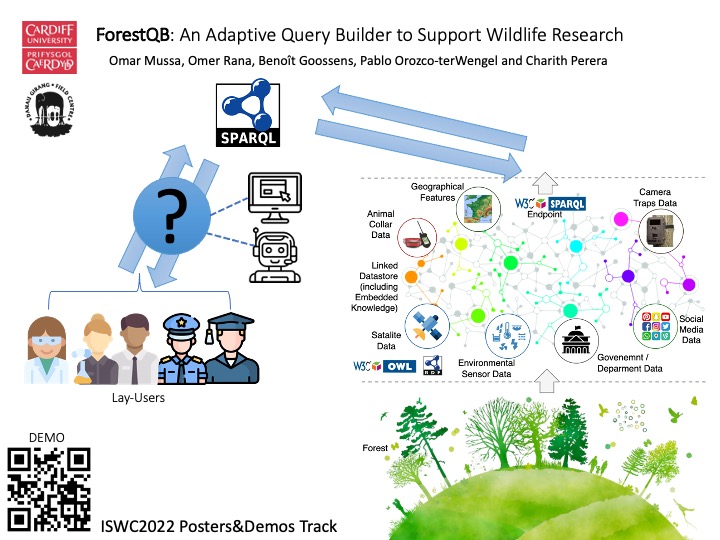
Linked data is a set of design principles for structuring information so that it becomes accessible and machine readable. When data are linked, the resulting graph becomes traversable and nodes are connected through meaningful relationships. Linked data breaks down information silos between formats and brings down fences between sources. However, it is challenging for non-expert users to retrieve linked data because doing so often requires an understanding of semantic query languages such as SPARQL. This project explores how to make linked data more accessible by allowing non-technical end users, such as bioscience researchers and wildlife conservationists, to perform their work more efficiently through graphical and conversational interfaces backed by large language models. The resulting system, ForestQB, integrates these interfaces to support adaptive query building for wildlife research and biodiversity conservation.
The approach combines graphical interfaces with conversational AI techniques to facilitate efficient linked data retrieval. Naive users do not need experience with SPARQL or any other query language, while expert users can perform their tasks more quickly. The system leverages large language models to translate natural language queries into structured SPARQL queries, bridging the gap between user intent and the technical requirements of semantic data access.
ForestQB was developed in collaboration with the Danau Girang Field Centre. It targets wildlife research and biodiversity conservation use cases, enabling researchers to explore complex ecological datasets without requiring specialised technical knowledge.
Team





Partners

Repositories
forest-qb
ForestQB — A query builder toolkit for exploring observational Linked Data in wildlife research and conservation. Combines a GUI with a conversational UI (Rasa chatbot) and LLM integration to make SPARQL endpoints accessible to non-experts. Built with Vue.js.
forest-qb-data
Experiment data repository for the ForestQB project — Enhancing Linked Data Retrieval in Conversational UIs Using Large Language Models. Contains RDF datasets, SPARQL query generation experiments, LLM evaluation metrics, and prompt testing results (WISE 2024).